Lock-free webserver using channels in Rust
Following on from my previous blog post about using Elm for the front end of a job scheduling app
(kronuz), this blog post delves into the details of the Rust webserver
and the methodology used to avoid shared mutable behind a Mutex.
I arbitrarily enforced the constraint after using Elm, where there are no mutable references. The
idea was to avoid conflating database mutation with database synchronisation.
Since the kronuz webserver and database are simple, it was a good candidate to test an API purely
based around channels.
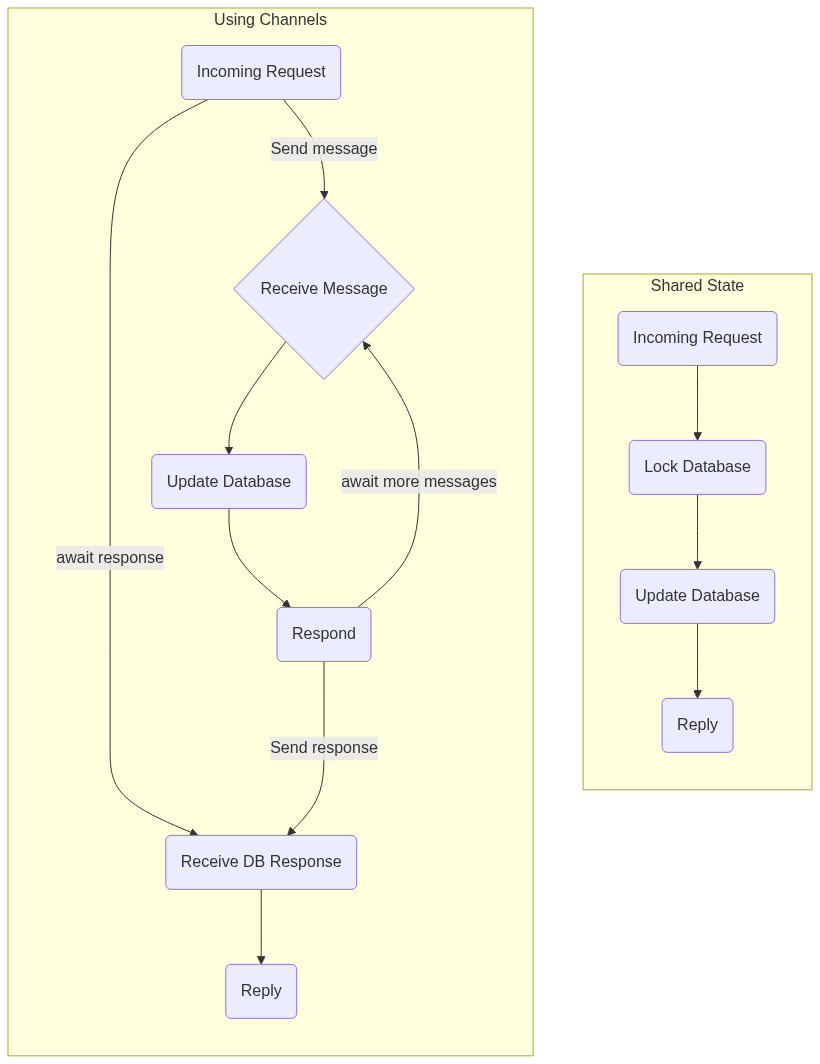
The database definition is simply defined as two maps, one of the users, and one of the current
sessions. Note that these are std::collections::HashMaps.
#[derive(Serialize, Deserialize)]
pub struct Db {
usrs: HashMap<UsrId, User>,
#[serde(skip)]
sessions: HashMap<UsrId, Session>,
}Upon the server starting, the database is deserialised and loaded into memory. This returns the
database itSelf, it is not until a spawn call that the message loop is spun up.
The spawn call consumes the database, setting up a bounded channel, and spawning the message
loop with the database and the receiver of the channel.
The webserver is backed by tokio, so the channels are tokio's variants. I also leak the sender,
effectively letting the sender become a static reference that will live for the rest of the
server's life. This is primarily done to gain copy semantics, rather than having to annotate a
.clone() everywhere. This becomes especially ergonomic when working with closures and async
blocks requiring move semantics, avoiding having to bind the clone to a temporary variable.
impl Db {
pub fn spawn(self) -> DbTx { // consumes self
let (tx, rx) = channel(100_000); // bounded channel
tokio::spawn(run(rx, self)); // spawn the message loop (moving self)
let tx = DbTx(Box::leak(Box::new(tx))); // leak the transmitter
tx
}
}
// the transmitter is a static reference.
#[derive(Copy, Clone)]
pub struct DbTx(&'static Sender<Dm>);It would be nice if DbTx could be defined using something like lazy_static, so that it does not
need to be passed as an argument into functions. Doing so would constrain how the message loop is
constructed, since the creation of the channel is invoked through
the spawn call, initialising the message loop. With lazy_static, the message loop would begin
with the first access of the transmitter. This makes sequentially initialising the database
impossible, something I want to avoid.
Fetching a user's project list
With the message loop running, the webserver then begins to process requests.
The API was well suited for use with warp.
As an initial example, let us walk through a GET of a user's list of projects.
The warp filter is defined as a path, an auth filter, and the JSON reply.
fn project(tx: DbTx) -> BoxedFilter<(impl Reply,)> {
let get_project_list = get()
.and(path!("api" / "v1" / "prj" / "list"))
.and(path::end())
.and(auth(tx))
.map(|x: User| reply::json(x.projects()));
// ... other project filters
}The auth filter is where we first utilise the database sender. The filter looks for two required
cookies, a user ID and the session token. It then passes these, along with the sender,
to the authenticate_session function. Here, the sender has two associated calls; get_usr and
get_session_token.
fn auth(tx: DbTx) -> BoxedFilter<(User,)> {
cookie("usrid")
.and(cookie("session"))
.and_then(move |u, s| async move {
authenticate_session(tx, u, s).await.map_err(reject::custom)
})
.boxed()
}
async fn authenticate_session(tx: DbTx, usrid: Token, token: SessionToken)
-> Result<User>
{
let usr = tx
.get_usr(usrid)
.await
.ok_or_else(|| Error::new("User not found"))?;
match tx.get_session_token(usr.id()).await {
Some(x) if x.token == token => Ok(usr),
_ => Err(Error::new("Session token expired")),
}
}Let's take a look at how these two calls are implemented. Both calls utilise the send associated
function, and both will return something from the database. For get_usr, the message that is
passed is GetUser, for get_session_token it is GetSessionToken. Both calls log any errors and
flatten the result. Since both functions do not need to give the reason for failure, they return
whether they found something or not as an Option.
impl DbTx {
pub async fn get_usr(&self, id: impl Into<UsrId>) -> Option<User> {
self.send(Dm::GetUser, id.into())
.await
.log_debug()
.flatten()
}
pub async fn get_session_token(&self, id: UsrId) -> Option<Session> {
self.send(Dm::GetSessionToken, id)
.await
.log_debug()
.flatten()
}
// ...
}The shared send function is a helper to encapsulated the shared pattern of the API.
It takes the database message (note that it is a function, leveraging how enum variants behave as
constructors) and the query's value. It is a very generalised function, but it effectively boils
down to:
- Create a one-shot channel to receive the response from the database,
- Construct the
Request, packaging the one-shot sender, - Send the request,
- Await the response on the receiver of the one-shot channel.
impl DbTx {
async fn send<F, Q, R>(&self, dm: F, q: Q) -> Result<R>
where
F: FnOnce(Req<Q, R>) -> Dm,
{
let (tx, rx) = oneshot::channel();
let dm = dm(Req { query: q, resp: tx });
self.0
.send(dm)
.await
.wrapstd("database channel closed")
.log_warn();
rx.await.wrapstd("database channel closed")
}
}
enum Dm {
GetUser(Req<UsrId, Option<User>>),
GetSessionToken(Req<UsrId, Option<Session>>),
// ... others
}All this is happening on the consumer side of the API, but what about the message loop? Mentioned
before, this occurs within the run function, consuming the main receiver and the database. The
loop simply awaits a message from the sender and processes it!
Following the example, for the GetUser message, it tries to find the user with the id,
responding through the one-shot channel the outcome.
All without locks. A similar process is employed for the GetSessionToken.
async fn run(mut rx: Receiver<Dm>, mut db: Db) {
use Dm::*;
fn respond<T>(tx: oneshot::Sender<T>, t: T) {
tx.send(t)
.map_err(|_| Error::new("database channel closed"))
.log_warn();
}
while let Some(m) = rx.recv().await {
match m {
GetUser(Req { query: id, resp }) => {
let x = db.usrs.get(&id);
respond(resp, x.cloned());
}
GetSessionToken(Req { query: usrid, resp }) => {
let t = db.sessions.get(&usrid).copied();
respond(resp, t)
}
// ... other message variants
}
}
}It is important to recognise that any interaction with the database is synchronised.
Compared to a database which might use fine-grained locks, any relational updates will happen
sequentially, and there is no requirement for lock ordering or fancy lock ordering APIs. This
example is just a simple query, a RwLock could handle this with multiple readers. Well let us
take a look at a mutating message.
Deleting a project
In a similar style to the previous example, deleting a project routes through an authorised endpoint. Let's just focus on the sender function:
impl DbTx {
pub async fn delete_project(&self, id: UsrId, prj: PrjId) -> Result<User> {
let usr = self
.send(Dm::DeleteProject, (id, prj))
.await
.and_then(|x| x)?;
prj::delete(usr.clone(), prj).await.map(|_| usr)
}
}So the function uses the send infrastructure to delete the project reference from the user. I
won't paste the code, since it simply updates the user's projects list, and responds with the
updated user, in the message loop. But notice how the removal of the project data is done outside
of the message loop! This is one of the benefits of this style of concurrency. Removal of the
project data is a disk operation, definitely slower than updating the in-memory user's information.
It could go into the message loop, with poor performance, so it goes cleanly outside the
loop. The loop, with its clear while, highlights that operations need to be concise and
performant. The same can be achieved with locks, the function that deletes the project can drop
the lock before doing the disk operation. But you have to remember to do so. This API makes it
much more clear that a blocking operation in the message loop will be blocking further processing
of the messages.
Summary
I have only shown a few functions of the API, it is worth noting that there are 12 variants of
database messages (not all respond, some like Persist, are directives). The message loop is 101
lines. How this style scales, I am not sure, since kronuz has very lightweight requirements for its
webserver.
The style is, in my opinion, very focused, and I can see that adding more messages or refactoring
could avoid potential performance traps, along with keeping the database interactions all within a
single function making it easier to read and understand.
It also allows for refactoring of more complex relational data structures without the worry of
ensuring lock order when accessing or mutating them. This is a very important benefit that is not
immediately obvious.
This style is likely to continue to be my favoured paradigm for future projects of a similar nature,
it composed well with warp's API, and is more functional through passing messages rather than
using locks.
If you want to read about my thoughts of using Elm to create the kronuz front-end, see my previous post. If you haven't already, checkout kronuz to see the end product, I think it's a pretty neat project!